

We can also talk about the Management Information System, Data Ware House (DWH), Business Intelligence (BI) or anything else; in any case, it is a management decision-making support system. For a better understanding, it is a system providing information about the state of the company – financial, material and operational, also necessary for the right management decisions at a given time.
As part of its day-to-day operation, the company uses a business-transaction, ERP system: for example Billien and others. The transaction system provides the day-to-day running of the company and covers its key processes: contractual relationships, billing, warehouse management, readings at delivery points, order management, for example, the exchange of electric meters and so on.
DWH is not a transaction system. So, WHAT is it, actually? Let’s take a closer look at DWH…
Data, information, knowledge
It is important to distinguish between data, information and knowledge. Data are individual facts recorded in a database – male, Joseph, 190, 95, 43, blue, black, high school. Data simply exists on its own and does not provide any relevant information. If we put the data in context – gender, name, height, weight, age, eye color, hair color, educational attainment – we get informationaboutthe person. We see that he is a middle-aged, relatively tall man with a corresponding weight. Such information is important in certain situations for someone, say, for the head of the personnel department in the process of hiring a new employee. We can note that not all the data that is available constitutes the necessary information. Apparently, eye and hair color is not important when hiring a new person for a company. Information and about age and weight may be important in physically demanding occupations, information about educational attainment is almost always important. Thus, it is clear that one data source produces different information needed in different situations. If we further arrange the information in the necessary structure, we get knowledge. Thus, knowledge is made up of information in context – for example, based on information about the age and weight of several people, we may notice (gain knowledge) that weight increases with age for most people – of course, there may be exceptions J. And based on the knowledge, a decision can be made – even if only as obvious as to adjust diet and start exercising. Or, based on some knowledge of how the company’s financial situation has evolved over time, we can take out a bank loan, hire or fire more people, start an investment project, etc., or make a whole series of decisions. Clearly, if decisions are made without the necessary knowledge, or at least information, the consequences can be quite bad. To give one more example, by using information on the gas consumption of a certain type of customer over a certain period – for example, several years – we can learn that there is a clear relationship between the outside temperature and the amount of consumption. We can further use such knowledge to predict consumption based on predicted temperature. And if we can estimate – fairly accurately – how the consumption of a large group of consumption points will evolve, we can adjust the conditions on the distribution network – for example, the states of the control stations and the capacities of the gas storage tanks – to this in advance. That is, based on the knowledge (temperature vs. consumption, predictions) we make a certain decision (adjustment of the ratios on the network). But sometimes information about the size of consumption may not be enough, we need more detailed information – what is the consumption by type of consumption point, i.e. household, small, medium and large consumption.
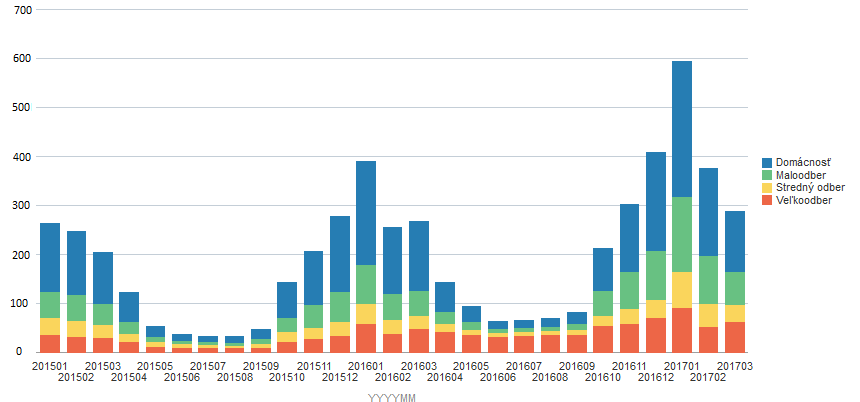
The chart below is based on consumption data for a given type of consumption point. Based on the above graph/report – i.e. information – we can derive an understanding of the seasonality of consumption based on the time of year, i.e. temperature. At first glance, it is also clear that household consumption is subject to seasonal influences much more than, for example, the consumption of the wholesale category, which is a consequence of the self-evident fact that gas is used in households for heating. The on-line transactional systems, such as Billien, which the company uses on a daily basis in its operations – namely warehouses, contracts, orders, deductions, invoicing, the daily complex calculation operations carried out within the market operator – produce large amounts of data every hour and every minute, in a wide variety of forms (numbers, texts, images, binary files, etc.) and in interrelationships with each other. Data from which the necessary information can be extracted. The question, of course, is how to extract information from gigantic amounts of data. Example – a manager from the metering department needs summary information on electricity consumption in the Banská Bystrica region for March 2016 for consumption points in the large consumption category, i.e. OM with annual consumption greater than 400 MWh per year – which is a specific requirement for extracting information from a lot of data. Or – yes – we can say that this is a classic report. So we just need to know the data model of the transactional application perfectly, we just need to know the SQL language very well, have accesses to the production database, write the appropriate database query and run it at the appropriate time so that we don’t affect the operation of the transactional system. Or we can use DWH or BI, click a few times and view the report in seconds.
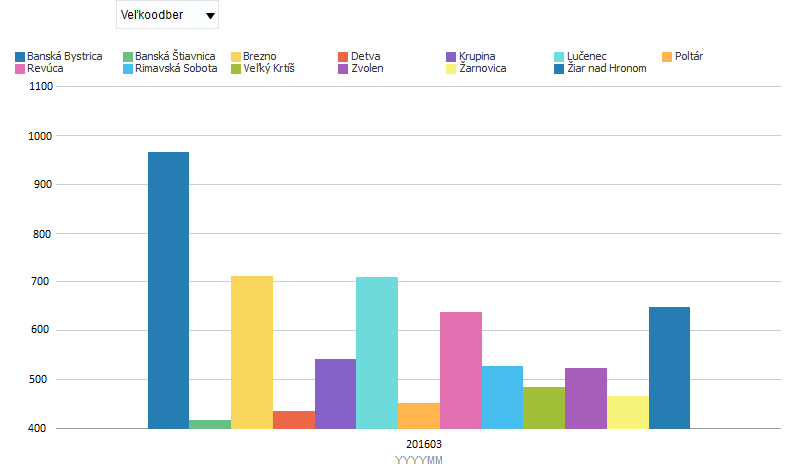
So the basic function of DWH and BI is to provide different views of the data depending on what information we need to obtain.
How the whole thing works
These examples have one thing in common: they look at one type of data (consumption) from different perspectives – in terms of time, region or type of consumption (household, large consumption) – they provide different information derived from the same facts. Within DWH, we have a specific fact stored, which is linked to several dimensions. As a matter of fact, consumption is uniquely associated with a delivery point type and is located at a specific address in the given region. Consumption, of course, is measured in time or, at a certain time interval (days, years, etc.). Time, address/region, type of delivery point are the dimensions through which we look at the fact (consumption). The dimensions thus create a context that gives us specific information from facts/data.
The data structure of DWH consists of facts, respectively, or fact tables, associated with dimension tables. Fact tables and dimension tables comprise the STAR scheme and this represents the core of the entire system.
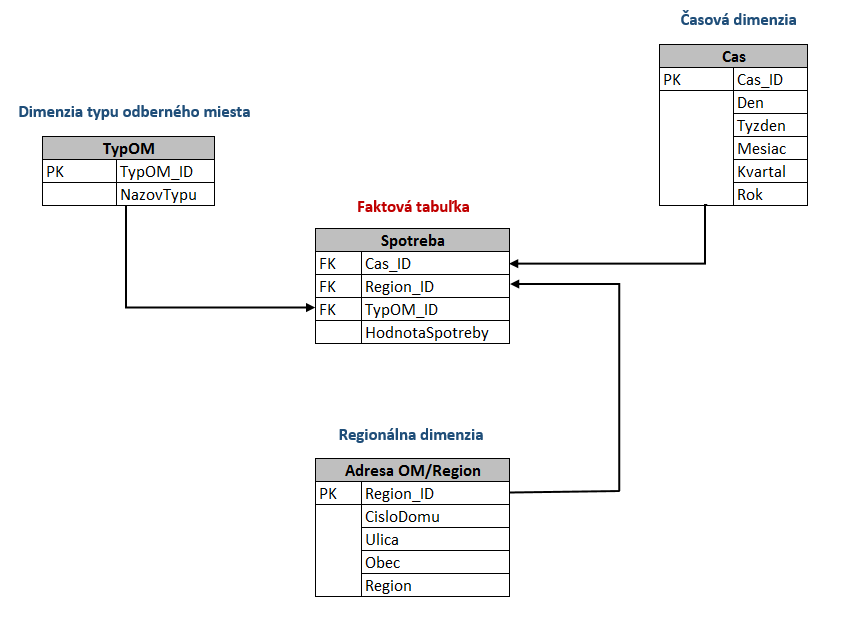
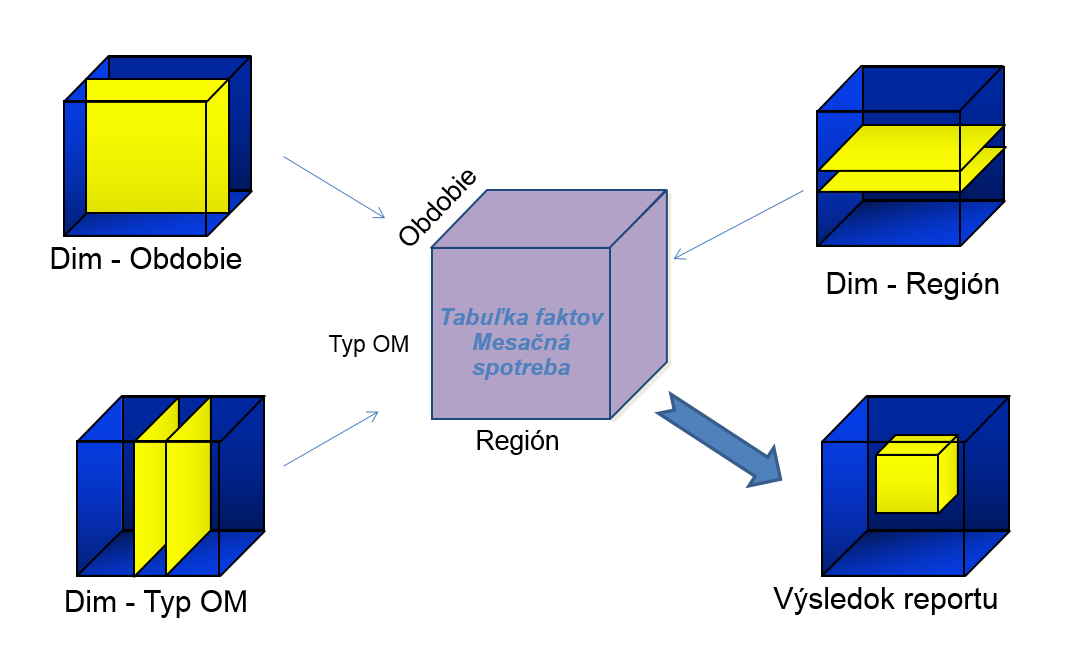
THE PRINCIPLE OF AGGREGATIONS BY DIMENSIONS
There is often a requirement to aggregate outputs, e.g. according to time. We want to know the total consumption of all delivery points for the whole year according to regions. It would also be quite reasonable to divide the total annual consumption according to regions into quarters or months. And then go back to summary annual consumption. Do we instead prefer to see annual / quarterly / monthly consumption according to the type of delivery point? Or from the total amount do we want to only select a specific region and then divide the total consumption within the selected region into individual districts, municipalities or even streets?
It is almost impossible to generate reports on the spot according to these requests directly from a transaction system database or even from multiple source systems. Each request would require the adjustment of the relevant selection criteria in the SQL command and, of course, a competent person/ people who understands the whole thing; and which a company can use elsewhere and in a definitely more efficient way.
The DWH is innately tailored for reporting based on various criteria: we get the answer within a few seconds. The principle of the OLAP cubes allows you to perform the necessary aggregations in advance, for example in the time dimension.– If, let’s say, we have daily consumption for delivery points in different regions available, the DWH automatically calculates and saves weekly, monthly and annual sums of consumption according to region, and when requested to generate a report, it only “pulls them out” into the report, which radically increases the speed.
Report preparation tools
DWH, or BI provides the user with numerous tools for the preparation of reports. When data is safely stored in the STAR schemes or other similar structures, we can put together reports as necessary using UI tools. It is possible to set multiple access levels to different types of data and to set access security.
Reports can be predefined or optional. The first ones can be run by a DWH user directly and create others as needed. Dimensions and facts create a large number of combinations, and it is possible to put together a report for each individual dimension combination.
A special form of reports is dashboards. These are minimalist reports showing the actual status of a certain quantity against the set criteria: KPI (Key Performance Indicators). An example is the trend of sales development over time. The company management for each period of the year will set expectations, then compared to the actual status and displayed in a transparent form within the dashboard. In this way, the manager in charge has a real-time, instant information, which can be used to make decisions operatively.
How the data gets into the DWH
Simply through the ETL process, i.e. through the process of Extractation, Transforming, and data Loading. Data will be downloaded from multiple source systems (Extract), modified and adapted as needed (Transform) and subsequently stored in the STAR DWH (Load) schemes. Data transformation is typically needed in cases where one entity – such as an invoice – is represented in different ways in multiple systems.
In preparing the DWH it is necessary to define information requirements/reports/ dashboards and identify the data sources that make up the information. Through specific tools, the required data from source systems are extracted, cleaned, transformed, and stored in prepared DWH structures. The process of creating tools for extracting, cleaning, transforming, and storing data is unique and relatively complex for each project and represents a large part of the DWH creation project.
The implementation of the DWH database through ETL processes has two phases in the most cases: the load will be executed in the DWH implementation, when the DWH uploads historical data from one or several systems over the required history period. The initial load is a one-time demanding process that is not repeated.
During the DWH operation, new data that originated in source systems during the previous day are recorded repeatedly and on a daily basis at a defined time (usually at night). Historical data do not change in this case.
This ensures that the DWH data are always up to date as well as accurately and faithfully represent the true status of the company.
One truth principle
The DWH collects data from multiple sources and provides comprehensive information to anyone who needs and uses it. Transactional systems required for running a business: CRM, invoicing and accounting, warehouses, HR, etc. live their lives, and all that is required of them is that at regular intervals once a day they upload new data to the DWH. The DWH represents the source of the only truth needed for responsible decisions at all levels of the company management.
Autor: Peter Melich

